지난번에는 데이터 테스트 중 Cross-sectional dependence(CSD) test - CDp 모델에 대해서 학습해 봤습니다.
이어서 데이터 내에 CSD가 유의하다고 가정했을 때, Panel unit root test 과정에 대해 이어서 학습해보도록 합시다.
먼저, 시계열 데이터에 대해 배운 뒤, 순차적으로 Panel unit root test까지 알아보도록 하겠습니다.
▶️ 단순 시계열 모델이란?
1. 단순시계열 모델 (AR 모델)
과거의 값으로 현재를 예측하는 가장 기본적인 수학 모델을 말합니다.
단순시계열 모델 중 가장 간단한 형태인 AR(1) 모델을 통해 배워보도록 하죠.
1) AR 모델 산출식
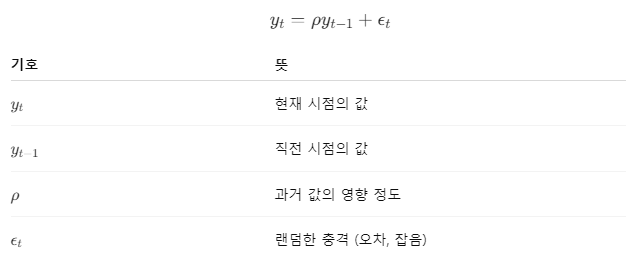
현재의 데이터(yt)는 과거 데이터(yt-1)과 오차(ϵ)의 합으로 만들어진다는게 시계열 모델입니다.
이 산출식에서 주요하게 봐야할 인자는 ρ 인데요. 좀 더 자세히 알아보도록 하죠.
2) ρ (로우)
ρ 란 단순 시계열 모델에서 과거의 값이 현재의 값에 얼마나 영향을 주는지를 수치로 나타낸 값입니다.
ρ는 단순 선형회귀를 하여 구하게 되는데, 이 값은 소프트웨어로 선형회귀시 자동으로 추출됩니다.
이때 발생한 ρ값에 따라 아래와 같이 해석을 할 수 있습니다.

ρ가 1에 가까울 수록 단위근(unit root)가 있다고 해석될 수 있습니다. 그렇다면 단위근은 무엇일까요?
단위근(unit root)는 시간이 지나도 평균값으로 돌아오지 않는 시계을을 말합니다. 예를 들어, 물가가 10년째 계속 오르고 있는데 단위근이 있다면 평균값으로 돌아오지 않는다는 걸 의미합니다.
자, 이제 단순시계열에 대해 이해했으니, Panel unit root에 대해 알아보도록 하죠.
▶️ Panel unit root test
1. Panel unit root test란?
Unit root test 란 시간의 흐름에 따른 데이터의 안정성/변동성을 확인하는 과정을 의미합니다. 여기에 Panel이 붙으면 단순히 한 국가, 하나의 변수만 테스트하는 것이 아니라 여러 단위으 데이터를 동시에 보고, 각각 단위근의 여부를 검정하는 방법을 말합니다. 보통 국제 데이터 분석에서 많이 사용되곤 합니다.
2. Test Process
2.1 Cross-sectional dependence test
Panel unit root test 전, 우리는 CSD test를 진행하여 변수 사이에 서로 영향성이 있는지를 확인해야 합니다.
CD test 결과에 따라 사용하는 Panel unit root test model 이 다르기 때문입니다.

그렇다면, 우리가 이전에 배웠던 CSD test를 진행하여, 데이터 간에 CSD가 있다고 가정해볼까요?
2.2. Panel unit test 모델 선정
이때 많이 사용하는 테스트로는 CADF, CIPS가 있습니다. 오늘은 이 2가지에 대해 알아보도록 하죠.
2.2.1 Cross-sectionally Augmented Dickey- Fuller test (CADF)
CADF는 각 국가의 시계열 분석과 더불어 전체 변수의 평균의 영향도 함께 고려하는 테스트를 말합니다.
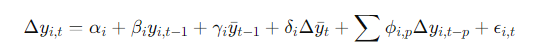

자 여기서 가장 중요한 변수는 β(단위근 계수)임을 인지하고 절차를 따라가보도록 하죠!
1) 전체 변수의 평균 시계열 산출

이 값을 전체 공통 요인(common factor)로 보고 CADF 식에 넣습니다.
2) 각 국가별로 CADF 회귀분석을 진행하여 β 값을 구할 수 있도록 합니다.
3) β 에 따른 해석

그렇다면 β 가 음수일 경우에 데이터가 안정적임을 나타냅니다. 하지만, 아직 데이터의 유의성을 판단하기에는 섣부릅니다. 우리는 p-value를 통해 해당 데이터가 우연히 나온 것인지를 판단해야하기 때문이에요.
4) p-value 분석
회귀분석을 통해 p-value를 산출하고, 이 값을 β 값과 함께 고려하여 데이터의 유의성을 판단할 수 있습니다.
β < 0 이고, p-value < 0.05 일 경우, 해당 시계열 데이터는 정상(stationary)이고, 통계적으로 유의하게 확인되었다는 판단을 내릴 수 있죠.
2.2.2 Cross-sectionally augmented IPS test (CIPS)
CIPS는 CADF의 업그레이드 버전이라고 생각하면 됩니다. 모든 변수에 대해 CADF 통계량을 평균을 내어, 패널 전체에 대한 단위근 여부를 검정하는 방법을 말하거든요.
1) CADF 회귀식을 각 변수에 적용
각 변수에 대해 회귀식을 산출합니다.
2) 각 변수의 CADF t-통계량에서 β 값 산출 및 평균

회귀분석을 통해 얻어낸 T ( β ) 값을 평균을 내면, CIPS 값이 나오게 됩니다.
3) CIPS 값과 임계값(critical value) 비교

Peasaran (2007)의 임계값표와 CIPS 값을 비교하여, CIPS 값이 기준보다 작으면 단위근이 없음 (정상성 有)으로 판단합니다.