▶️ Cross-sectional dependce (CSD) 란?
CSD란 서로 다른 패널 단위 사이에 오차항, 관측값 간 상관관계를 의미한다.
예를 들어, 국제 유가가 상승하면 모든 국가 인플레이션이 동시에 상향되는 것과 같이, 다른 단위지만 영향을 미치는 관계라고 이해하면 된다.
이때ㅡ 여러 데이터를 활용하여 회귀모형 분석을 진행할 때, 데이터 간 CSD가 있을 경우 여러 문제가 발생하므로 CSD test를 통해 데이터 간의 상관관계를 검사하는 과정을 거치게 된다.
자, 일단 순차적으로 일반적인 패널 회귀모형부터 이해해보자.
▶️ 일반적인 패널 회귀모형
1. 패널 데이터란 무엇일까?
여러 개의 단위를 시간에 따라 반복적으로 측정한 데이터를 의미한다.
예를 들어서, 여러 국가(단위)를 연도(시간)별로 GDP(변수)를 측정한다고 하면, 다른 단위를 가진 변수를 시간에 따라 측정하게 되는데, 이를 패널 데이터라고 한다.
2. 회귀모형이란 무엇인가?
X가 바뀔때, Y는 얼마나 바뀌는가를 알아보는 수학 모델이다.
예를 들어, 재생에너지 비중이 1% 늘어났을 때 인플레이션은 얼마나 변하는가를 수식으로 보고자 할 때, 회귀모형을 쓰게 된다.
3. 일반적인 패널 회귀모형 수식

자 그럼 위에 들었었떤 예시를 활용한 변형된 수식을 써보자.

이렇게 재생에너지 비중에 따른 인플레이션 영향을 판별하는 회귀모형이 만들어진다.
▶️ CSD를 고려하여 회귀분석을 해야하는 이유?
그렇다면 우리는 왜 CSD를 고려해서 회귀분석을 진행해야할까?

자, 다시 일반 회귀모형의 수식을 봐보자.
이 식에서 우리가 알 수 없는 것은 오차항( ϵ )에 대한 부분이다. 일반적으로는 서로 독립적이라고 가정하고 넘어가지만, 만약에 CSD가 존재한다면 아래와 같은 문제가 발생한다.
1) 표준오차 과소추정에 따른 유의성 오류
보통 해당 변수가 통계적으로 유의미함을 따질 때 표준오차로 판단할 수 있다. 이때 데이터 간에 CSD가 있는데 무시할 경우에는 표준오차가 실제보다 작게 계산되므로, 최종 결론(통계적으로 유의하다)이 잘못 도출 될 수 있다.
2) 계수추정값이 편향되어 잘못된 정책 시사점 도출
계수( β 등)의 추정값이 잘못 계산될 수 있고, 해당 결과값에 따른 정책 시사점 또한 잘못 도출되게 된다.
이러한 문제를 방지하기 위해 Cross-sectional dependence test를 통해 데이터를 기존 방식으로 분석해도 되는가를 점검해야만 한다.
▶️ Cross-sectional dependence test
CSD test를 진행하는데는 많은 방법론이 존재한다.
우리는 그 중에 대표 방법론인 Pesaran's CD test (Pesaran(2014))를 통해 테스트의 절차를 이해해보고자 한다.
1. Peasran's CD test란?

이 방법론은 단위 간의 오차의 쌍별 상관계수의 평균을 계산하는 방법을 말하며, 이 값이 통계적으로 크면 CSD가 존재하는 것으로 보고, 귀무를 기각한다. 상기 식의 경우 이해를 돕기 위해 예시를 반영하여 N과 T를 설명했다.
1) 쌍별 상관계수 평균
- 상관계수란, 두 개의 변수가 비슷하게 움직이는지 보는 숫자를 뜻한다.
- 쌍별 평균이란, 변수 간 상관성을 하나하나 비교하여 전체 평균을 내는 것으로, 전체적으로 얼마나 비슷한지를 보는 지표이다.
2) 귀무가설, 대립가설
- 귀무가설(H0)이란 변수 사이에 상관관계(의존성)이 없다는 가정이다. 모든 변수쌍 간 잔차(오차) 상관계수가 0이면, 아무 연관이 없다는 뜻으로 해석할 수 있다.

- 대립가설(H1)이란 변수 사이에 상관관계가 존재한다는 가정이다. 귀무가설이 기각되었을 때의 상태를 말한다.

2. Test Process
1) 잔차 산출
잔차 = 실제값 - 예측값
각 국가에서 회구분석을 진행하여 잔차(오차)를 구한다
2) 국가쌍 별로 상관계수 산출
해당 잔차가 다른 국가와 비슷한 패턴을 보이는지 확인해야하기 때문에, 시간 순서에 따라 나란히 배열하여 상관계수를 계산한다.

이제, 두 열 사이의 상관계수(ρ 한국, 미국)를 구한다.

만약 국가가 더 있다면, 전체 국가쌍 (ex. 한국-미국. 한국-일본. 미국-프랑스 등)을 반복한다.
총 쌍의 수(비교해야하는 쌍의 개수)는 아래 수식을 통해 구할 수 있다.

3) CD test 통계량 산출 및 유의성 판단
이렇게 산출한 상관계수의 전체 평균을 계산한 뒤에,
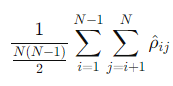
이를 통해 얻은 상관계수의 평균값은 단지 숫자에 불과해요.
그래서 이 수치가 얼마나 크면 이상한건지 판단하기 위해서는, 표준화(정규화)를 통해 Z-값(표준 정규분포 값)으로 변환해서 통계 검정에 사용할 수 있도록 해줘야합니다.
아래 수식이 최종 CD 통계량을 나타내는 수식이에요.

4) p-value 계산
최종 값이 나왔으니, 통계검정의 마지막 단계로 이 값이 우연히 나올 확률을 계산해볼 차례에요.
그걸 p-value라고 합니다. CD 값은 대체적으로 표준정규분포를 따르니 아래와 같은 수식으로 정리할 수 있어요.

일반적으로 p의 값이 기준값(0.05)과 비교해 작으면, 우연히 나오지 않았다고 봅니다.
고로, 최종적으로 산출한 CD값이 p-value가 0.05 미만일 경우, 귀무가설(모든 변수는 독립적이다)은 기각되고 데이터 간에 CSD가 있다고 보게 됩니다.
그럼 일반적인 모델을 사용할 수는 없고 CSD가 반영된 모델을 사용해야한다는 결론을 낼 수 있답니다.
'Graduate School > Tool' 카테고리의 다른 글
| [Estimator] About Augmented Mean Group(AMG) - 보강된 평균그룹 추정법에 대하여 (9) | 2025.08.12 |
|---|---|
| [Estimator] About Common Correlated Effects Mean Group (CCEMG) - 공통상관효과 평균그룹 회귀모형에 대하여 (2) | 2025.08.11 |
| [Diagnostic Test] About Panel cointegration test (공적분 검사) (2) | 2025.08.09 |
| About The slope hommogeneity test (동질성 기울기) (0) | 2025.08.09 |
| [Diagnostic Test] About Panel unit root test (CADF, CIPS) (2) | 2025.08.08 |