PCSE(Panel Corrected Standard Errors, 패널 수정 표준 오차) 분석은 시계열적 특성과 횡단면적 특성을 모두 가진 패널 데이터를 다룰 때 사용되는 분석이다. 이 글에서는 PCSE 분석이 무엇인지, 어떻게 활용되는지에 대해 쉽게 설명하고자 한다.
▶️ PCSE 분석이란?
1) PCSE 정의
패널 데이터 회귀분석에서 표준 오차(standard error)를 보다 정확하게 추정하기 위한 방법이다.
일반적인 OLS(Ordinary Least Squares) 회귀분석은 오차항이 서로 독립적이고 분산이 일정하다는 가정을 따르지만, 여러 국가나 기업 등 오랜시간에 걸쳐 추적하는 패널데이터에서는 이러한 가정을 위반 하는 경우가 많기 때문이다.
2) 패널 데이터에서 발생하는 문제점
- 분산성 (Heteroskedasticity): 각 횡단면 단위(예: 국가, 기업)마다 오차의 분산이 다른 경우. 예를 들어, 대기업의 이익 변동성이 중소기업보다 클 수 있다.
- 자기상관 (Autocorrelation): 특정 횡단면 단위의 오차가 시간의 흐름에 따라 서로 영향을 미치는 경우. 예를 들어, 어떤 국가의 올해 경제 성장률 오차는 작년의 오차와 관련이 있을 수 있다.
- 횡단면 의존성 (Cross-sectional Dependence): 서로 다른 횡단면 단위의 오차가 특정 시점에서 서로 상관관계를 갖는 경우. 예를 들어, 글로벌 금융 위기는 여러 국가의 경제에 동시에 비슷한 충격을 주어 오차들이 서로 연관되게 만든다.
이러한 문제를 무시하고 일반적인 회귀분석을 진행하게 된다면, 표준 오차가 실제보다 작게 추정되고, 실제로는 유의하지 않은 변수가 통계적으로 유의하다는 잘못된 결론을 도출하게 될 수도 있다. 그렇기 때문에 PCSE 추정을 통해 이분산성, 자기상관, 횡단면 의존성을 모두 고려하여 표준 오차를 수정하고 보정해주는 과정을 거치게 되는 것이다.
3) 언제 PCSE를 사용할까
다양한 분야의 시계열-횡단면(Time-Series Cross-Section, TSCS) 데이터 분석에서 널리 사용된다. 특히 다음과 같은 상황에서 PCSE 모델을 고려해볼 수 있다.
- 데이터의 기간(T)이 횡단면 단위의 수(N)와 비슷하거나 더 클 때 (T ≥ N)
PCSE는 원래 이러한 "장기 패널(long panel)" 데이터에 적합하도록 개발되었다. 정치학 연구에서 흔히 볼 수 있듯이, 수십 개의 국가를 수십 년에 걸쳐 분석하는 경우가 대표적이다. - 횡단면 간 상호의존성이 의심될 때
분석 대상인 국가, 기업, 지역 등이 서로 경제적, 정치적으로 밀접하게 연관되어 있어 외부 충격의 영향이 확산될 가능성이 있을 때 유용하다. - FGLS(Feasible Generalized Least Squares)의 대안을 찾을 때
FGLS 역시 복잡한 오차 구조를 다루는 방법이지만, 특히 T가 N에 비해 충분히 크지 않을 경우 표준 오차를 지나치게 과소추정하는 경향이 있다고 알려져 있다.
반면, 횡단면 단위의 수(N)가 기간(T)에 비해 훨씬 큰 단기 패널(short panel)의 경우 PCSE 사용에 신중해야 한다. 이러한 데이터에서는 고정 효과 모형(Fixed Effects Model)에 클러스터 강건 표준 오차(clustered robust standard errors)를 적용하는 것이 더 적절한 대안이 될 수 있다.
4) 다른 패널 분석 방법과의 차이점

▶️ PCSE 분석 절차
1. 기본 패널 회귀모형
1) 기본적인 선형 패널 회귀 모형

- : 번째 개체(국가, 기업 등)의 시점에서의 종속변수
- : 번째 개체의 시점에서의 독립변수 벡터 (K개의 독립변수)
- : 추정하고자 하는 회귀계수 벡터 ()
- : 번째 개체의 시점에서의 오차항
2) 행렬 형태로 변환

- : 종속변수 벡터 $()$
- : 독립변수 행렬 $()$
- : 오차항 벡터 $()$
2. OLS 또는 Prais-Winsten을 이용한 회귀계수(β) 추정
OLS 추정량은 오차항에 이분산성이나 자기상관이 존재하더라도 비편향성과 일관성을 만족하기 때문에 PCSE에서 회귀계수 자체는 OLS 추정량을 그대로 사용한다.

3. 회귀분석 결과로부터 잔차(e) 계산
1단계에서 추정한 회귀계수($\hat를 이용해 모델의 잔차(residual)를 계산한다. 이 잔차는 관측할 수 없는 실제 오차()의 추정치 역할을 하며, 오차의 분산-공분산 구조를 파악하는 데 핵심적인 재료가 됩니다.
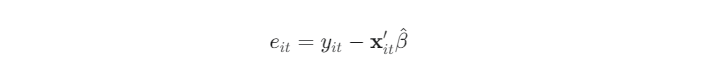
이 잔차들을 모아 잔차 벡터 $ ()$를 만든다.
4. 잔차를 이용한 오차항의 분산-공분산 행렬(Ω) 추정
이 단계가 PCSE의 핵심이다. 2단계에서 얻은 잔차를 사용하여, 패널 데이터가 가진 복잡한 오차 구조, 즉 이분산성과 횡단면 의존성을 반영하는 분산-공분산 행렬()을 추정한다.
먼저, 개체들 간의 동시대 상관(contemporaneous correlation)을 담는 $ 행렬 를 추정한다. 이 행렬의 각 요소($\hat)는 다음과 같이 계산된다.

- $\hat (대각항): 번째 개체의 오차 분산(Variance) 추정치 (이분산성을 반영)
- $\hat (비대각항): 번째 개체와 번째 개체의 오차 공분산(Covariance) 추정치 (횡단면 의존성을 반영)
이렇게 추정된 $\hat{\Sigma}$를 이용해 전체 오차항의 분산-공분산 행렬 $\hat ()$를 다음과 같이 구성한다.
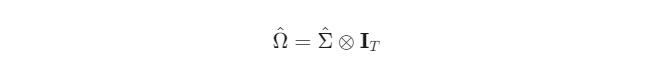
- : 크로네커 곱(Kronecker product)
- : $ 단위행렬(Identity matrix)
이 $\hat 행렬은 대각선 블록에 각 개체의 오차 분산을, 비대각선 블록에 개체 간 오차 공분산을 배치하여 패널 데이터의 복잡한 오차 구조를 수학적으로 표현한 것이다.
5. 샌드위치 추정량을 이용한 표준 오차 보정
마지막으로, 1단계에서 구한 OLS 회귀계수와 3단계에서 추정한 분산-공분산 행렬( $\hat )을 결합하여 분산-공분산 행렬을 계산한다. 이 형태가 마치 빵 사이에 내용물이 낀 샌드위치와 같다고 해서 샌드위치 추정량(Sandwich Estimator)이라고 부른다.

- : "빵"에 해당하며, 일반적인 OLS 분산 공식의 일부이다.
- : "고기" 또는 "내용물"에 해당하며, 3단계에서 추정한 복잡한 오차 구조( $\hatΩ$)를 반영하는 핵심 부분이다.
이 공식을 통해 계산된 $ 행렬의 대각선 원소에 제곱근을 취하면, 그것이 바로 이분산성, 자기상관, 횡단면 의존성을 모두 보정한 패널 수정 표준 오차(Panel Corrected Standard Error)가 된다.

이 보정된 표준 오차를 사용하면, t-통계량과 p-값을 더 신뢰성 있게 계산할 수 있으며, 결과적으로 더 정확한 가설 검정이 가능해진다.
6. t-통계량 산출
t-통계량은 두 집단의 평균 간 차이가 통계적으로 유의미한지, 아니면 단순한 우연에 의한 것인지를 판단하기 위해 사용하는 값이다.

여기서 회귀계수(Coefficient)는 독립변수가 종속변수에 미치는 영향력의 크기나 관계의 강도를 나타낸다. 예를 들어 교육 수준이 1년 높아질 때마다 소득이 100만원 증가한다는 분석 결과에서 100만 원이 바로 이 신호에 해당한다.
또한 표준오차는 우리가 추정한 회기계수가 얼마나 불확실하고 변동성이 큰지를 나타내는 값이다. 우리가 논의한 PCSE값이 여기에 해당한다.
고로 우리는 t-통계량 값에 대하여 아래와 같이 해석할 수 있다.

'Graduate School > Tool' 카테고리의 다른 글
| [Model] About Contingent Valuation Method(CVM, 조건부 가치 평가법) (8) | 2025.08.20 |
|---|---|
| [Estimator] About Augmented Mean Group(AMG) - 보강된 평균그룹 추정법에 대하여 (9) | 2025.08.12 |
| [Estimator] About Common Correlated Effects Mean Group (CCEMG) - 공통상관효과 평균그룹 회귀모형에 대하여 (2) | 2025.08.11 |
| [Diagnostic Test] About Panel cointegration test (공적분 검사) (2) | 2025.08.09 |
| About The slope hommogeneity test (동질성 기울기) (0) | 2025.08.09 |